
Atak przeciążeniowy potrafi zatrzymać sklep internetowy, portal urzędowy, system rezerwacji albo serwis informacyjny bez jednego włamania do bazy danych. Najczęściej chodzi o zalanie infrastruktury ruchem do tego stopnia, że legalni użytkownicy nie mogą się połączyć, a zespół techniczny zostaje zmuszony do działania pod presją czasu. W tym artykule pokazuję, jak taki mechanizm działa, po czym go rozpoznać, jak się przed nim zabezpieczyć i co zrobić, gdy usługa zaczyna się dusić.
Najważniejsze rzeczy, które trzeba wiedzieć o ataku na dostępność usług
- Celem ataku nie jest zwykle kradzież danych, tylko sparaliżowanie dostępności usługi i odcięcie użytkowników od systemu.
- Objawy bywają podobne do awarii, ale atak najczęściej daje skoki ruchu, dużą liczbę podobnych żądań i przeciążenie jeszcze przed warstwą aplikacji.
- Najlepiej działa obrona warstwowa: CDN, WAF, rate limiting, redundancja DNS, monitoring i gotowy plan reakcji.
- W pierwszych minutach liczy się dyscyplina operacyjna - zachowanie logów, kontakt z dostawcą, potwierdzenie skali i szybkie ograniczenie ekspozycji.
- W Polsce warto zgłaszać incydent do CERT Polska, a przy szantażu, sabotażu lub poważnych stratach także rozważyć zawiadomienie organów ścigania.
Czym jest atak na dostępność usług i dlaczego tak skutecznie blokuje ruch
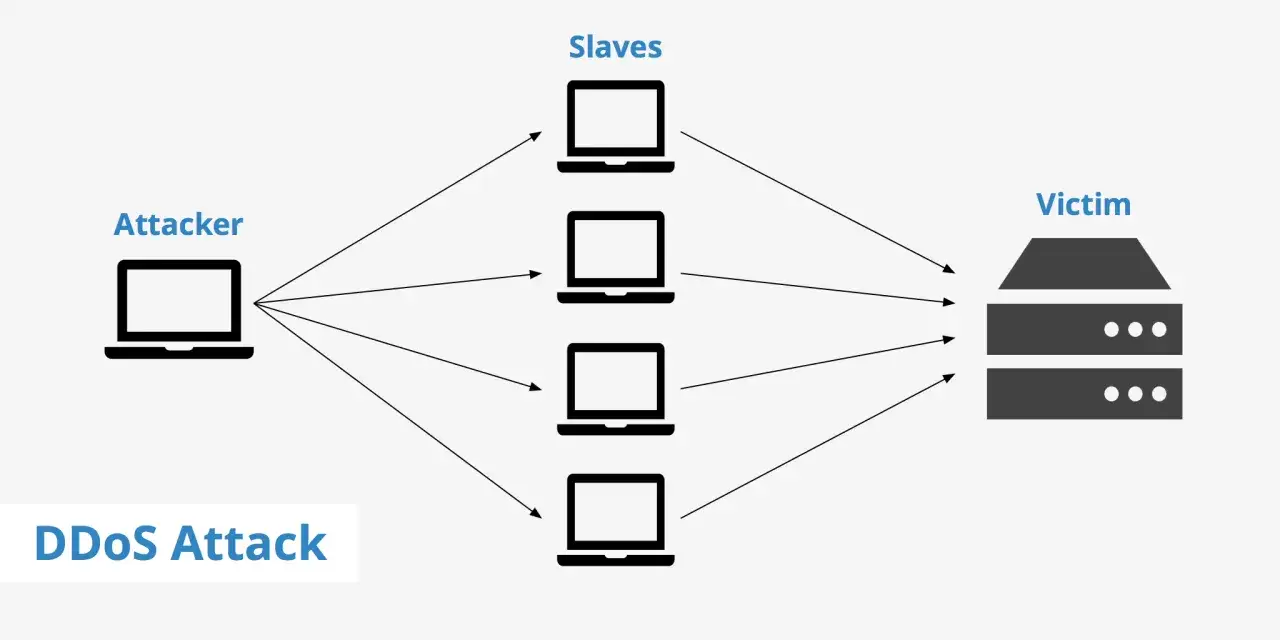
W praktyce to próba wyczerpania zasobów serwera, łącza, zapory albo samej aplikacji. Zamiast jednej osoby, która odświeża stronę, masz setki, tysiące albo miliony urządzeń wysyłających żądania jednocześnie. Usługa nie musi zostać złamana, żeby przestała działać - wystarczy, że nie nadąża z obsługą ruchu.
Najważniejsze rozróżnienie jest proste: w tym scenariuszu chodzi o dostępność, a nie o poufność czy integralność danych. Dlatego taki incydent nie zawsze zostawia ślad w postaci wycieku, ale może skutecznie odciąć klientów od panelu, płatności, API albo panelu administracyjnego. Z mojego punktu widzenia to właśnie ten aspekt bywa niedoceniany: firma patrzy na „brak włamania”, a użytkownicy widzą tylko niedostępny serwis.
Mechanizm jest zwykle rozproszony. Zamiast jednego źródła ruchu atakujący korzysta z botnetu, czyli sieci przejętych urządzeń, lub z technik wzmacniających natężenie ruchu. Wtedy ofiara nie blokuje jednego komputera, tylko musi odfiltrować ogromną falę pakietów, zapytań DNS, HTTP albo prób zestawienia sesji. Według ENISA, zagrożenia dla dostępności usług należały w 2024 roku do najpoważniejszych kategorii w europejskim krajobrazie cyberzagrożeń, co dobrze pokazuje, że to nie jest problem marginalny.
To prowadzi wprost do kolejnego pytania: jak odróżnić celowy atak od zwykłej awarii lub błędu konfiguracji.
Jak rozpoznać, że problemem jest atak, a nie awaria
Tu najłatwiej popełnić kosztowny błąd diagnostyczny. Sama niedostępność strony nie mówi jeszcze nic. Inaczej wygląda padnięty serwer po błędnej aktualizacji, inaczej problem z DNS, a inaczej ruch generowany przez rozproszoną sieć źródeł. Jeśli patrzę na taki incydent praktycznie, szukam przede wszystkim wzorca, a nie pojedynczego komunikatu o błędzie.
| Objaw | Co może sugerować | Co sprawdzić od razu |
|---|---|---|
| Skok liczby żądań w krótkim czasie | Atak przeciążeniowy lub błąd skryptu po stronie klienta | Metryki ruchu, kraj pochodzenia, adresy IP, user-agent, wzór zapytań |
| Serwer odpowiada wolno, ale nie jest w pełni offline | Atak warstwy aplikacji albo przeciążenie zasobów | CPU, RAM, kolejki połączeń, czas odpowiedzi aplikacji, logi reverse proxy |
| DNS działa niestabilnie | Problemy z infrastrukturą nazw lub celowe obciążenie | Rekordy DNS, TTL, ruch do serwerów nazw, stan dostawcy DNS |
| Awaria występuje tylko na jednym endpointcie | Wada aplikacji, niekoniecznie atak | Porównać logi błędów, wersję wdrożenia, ostatnie zmiany kodu |
| Ruch pochodzi z wielu geolokalizacji i powtarza podobny wzorzec | Silna przesłanka ataku rozproszonego | Łączyć dane z WAF, firewalla, CDN i operatora łącza |
Najbardziej podejrzane są sytuacje, w których usługa pada falami: działa przez chwilę, po czym znowu się dusi. Taki rytm często oznacza, że ktoś testuje zabezpieczenia, zmienia wektor ataku albo miesza kilka technik naraz. Wtedy trzeba myśleć nie tylko o „naprawie strony”, ale o całym łańcuchu dostarczania usługi.
Jeżeli chcesz patrzeć na to zawodowo, zapamiętaj jedno: atak nie musi wyglądać spektakularnie, żeby był skuteczny. Czasem to po prostu niewielkie żądania wysyłane masowo, które trafiają dokładnie tam, gdzie system ma najsłabszy punkt. I właśnie dlatego warto znać najczęstsze warianty.
Jakie warianty ataku spotyka się najczęściej
W praktyce obrona zależy od typu przeciążenia. Jedne ataki „zjadają” pasmo, inne wyczerpują tablice stanów w firewallu, a jeszcze inne uderzają w konkretną funkcję aplikacji, na przykład wyszukiwarkę, logowanie albo koszyk. Dlatego traktuję je jako różne problemy, nawet jeśli z zewnątrz wyglądają podobnie.
| Typ | Na czym polega | Co zwykle cierpi | Jak się temu przeciwdziała |
|---|---|---|---|
| Volumetric | Zalewanie infrastruktury ogromną ilością ruchu | Łącze, routery, przepustowość operatora | Filtrowanie u dostawcy, scrubbing, CDN, Anycast |
| Protocol | Wykorzystywanie kosztownych mechanizmów protokołów sieciowych | Firewall, load balancer, tablice połączeń | Ograniczanie stanów, reguły antyspoofingowe, tunning urządzeń brzegowych |
| Application-layer | Masowe, „udawanie prawdziwych” żądań do aplikacji | Backend, baza danych, kolejki, cache | WAF, rate limiting, cache, ochrona konkretnych endpointów |
| Reflection i amplification | Wykorzystanie zewnętrznych serwerów do wzmacniania ruchu | Przepustowość, infrastruktura DNS lub UDP | Blokady antyspoofingowe, współpraca z operatorami, filtrowanie źródeł |
| Multivektor | Łączenie kilku technik naraz | Cały stos usługowy | Plan reakcji, redundancja i szybka eskalacja do dostawców ochrony |
Najbardziej problematyczne są ataki mieszane, bo wymuszają zmianę obrony w trakcie incydentu. Najpierw trzeba odciąć zalew ruchu, potem sprawdzić aplikację, a na końcu upewnić się, że nie ma równoległego skanowania, włamania albo próby szantażu. To ważne również z perspektywy ochrony danych: samo przeciążenie nie musi oznaczać wycieku, ale może być zasłoną dymną dla innych działań.
Skoro wiadomo już, z czym można mieć do czynienia, przechodzę do tego, co daje realną odporność jeszcze przed pierwszym alarmem.
Jak budować odporność, zanim pojawi się kryzys
Najlepsza obrona zaczyna się długo przed incydentem. Nie kupuję jednej usługi i nie uznaję sprawy za zamkniętą, bo pojedyncza warstwa ochrony zwykle nie wystarcza. W praktyce liczy się zestaw rozwiązań, które ograniczają ryzyko na różnych poziomach infrastruktury.
- Włącz CDN i Anycast tam, gdzie to możliwe. Ruch jest wtedy rozkładany geograficznie, a serwis mniej zależy od jednego punktu wejścia.
- Ustal limity ruchu dla logowania, wyszukiwarki, formularzy i API. Najczęściej atak trafia właśnie w najbardziej kosztowne endpointy.
- Postaw na WAF i reguły rate limiting. To nie jest cudowny lek, ale dobrze ustawiony filtr potrafi odsiać dużą część śmieciowego ruchu.
- Zadbaj o redundancję DNS i łącza. Jeżeli jeden dostawca ma problem, drugi może utrzymać usługę przy życiu.
- Monitoruj ruch w czasie rzeczywistym. Bez metryk nie odróżnisz ataku od własnego błędu wdrożeniowego.
- Przećwicz plan reakcji. Zespół, który raz na kwartał symuluje incydent, reaguje szybciej i mniej chaotycznie.
W Polsce warto myśleć o tym również formalnie. CERT Polska przyjmuje zgłoszenia incydentów i w praktyce prosi, by robić to jak najszybciej, najlepiej nie później niż w ciągu 24 godzin od wykrycia problemu. To ważne, bo szybkie zgłoszenie zwiększa szansę na zebranie danych, zanim logi zostaną nadpisane albo zanim atak zmieni charakter.
Ta część przygotowań ma jeden cel: skrócić czas od pierwszego niepokojącego sygnału do sensownej reakcji. A gdy atak już trwa, liczą się przede wszystkim pierwsze minuty.
Co zrobić w pierwszych 30 minutach ataku
W kryzysie najłatwiej działać impulsywnie. Z doświadczenia wiem, że to właśnie wtedy padają najdroższe decyzje: ktoś restartuje wszystko bez analizy, ktoś inny wyłącza logowanie, a jeszcze ktoś próbuje „przeczekać problem”. Lepiej zrobić kilka rzeczy po kolei niż dużo rzeczy chaotycznie.
- Potwierdź skalę incydentu - sprawdź, czy problem dotyczy jednego endpointu, całej aplikacji czy całej warstwy sieciowej.
- Zabezpiecz logi - nie kasuj ich i nie nadpisuj, bo będą potrzebne do analizy technicznej i ewentualnego postępowania.
- Skontaktuj się z dostawcą hostingu, CDN lub operatorem - oni często mogą odsiać ruch szybciej niż lokalny zespół.
- Włącz lub zaostrz reguły ochronne - challenge pages, limity, dodatkowe filtry, blokady krajów lub ASN, jeśli wzorzec ruchu to uzasadnia.
- Odizoluj najbardziej obciążane zasoby - czasem warto chwilowo ograniczyć panel administracyjny albo kosztowne funkcje.
- Ustal jedną ścieżkę komunikacji - jedna osoba zbiera informacje, druga podejmuje decyzje, reszta nie improwizuje.
- Zgłoś incydent do CERT Polska i dołącz to, co masz już teraz: znaczniki czasu, fragmenty logów, adresy IP, zrzuty ekranów, opis wpływu na usługę.
Najważniejsze jest to, by nie pomylić „szybkiej reakcji” z „działaniem w ciemno”. Jeżeli atak trwa, ale usługa jeszcze w ogóle odpowiada, lepiej najpierw ograniczyć wektory przeciążenia niż robić pełny restart środowiska. Restart może dać chwilowy oddech, ale równie dobrze odciąć Cię od danych, których potrzebujesz do obrony.
Po opanowaniu pierwszej fali zaczyna się etap ważniejszy dla śledztwa i bezpieczeństwa formalnego niż dla samej techniki.
Jak wygląda zgłoszenie i współpraca z organami w Polsce
Jeżeli incydent dotyczy polskiej infrastruktury, strony .pl albo systemu działającego w kraju, warto potraktować zgłoszenie jako element obrony, a nie formalność. CERT Polska zajmuje się również atakami typu DoS i DDoS, a w praktyce pomaga w sytuacjach, gdy atak ma źródło w Polsce lub dotyczy zasobów krajowych. To ma znaczenie, bo nawet jeśli ruch przychodzi z zagranicy, analitycy mogą go skorelować z innymi zdarzeniami i przekazać sprawę dalej.
Jeśli sprawa wygląda na szantaż, sabotaż albo celowe wymuszenie przerwy w działaniu, wchodzi też perspektywa organów ścigania. W takich przypadkach nie chodzi już tylko o dostępność strony, ale o dowody, zamiar i szerszy kontekst zdarzenia. Z punktu widzenia śledczego najcenniejsze są: dokładny czas rozpoczęcia ataku, charakter żądań, próbki logów, informacje o tym, co było celem i jaki był rzeczywisty wpływ na użytkowników.
W praktyce dobrze działa prosty zestaw materiałów do zgłoszenia:
- dokładny czas wykrycia problemu,
- adresy IP lub zakresy, jeśli są widoczne,
- fragmenty logów z reverse proxy, firewalla, WAF i aplikacji,
- opis tego, które usługi przestały działać,
- informacja, czy pojawiło się żądanie okupu, groźba albo komunikat polityczny.
W sprawach przeciążeniowych często decyduje nie tylko technika, ale i porządek dowodowy. Dobrze spisane zdarzenie, zsynchronizowane zegary systemowe i zachowane logi robią większą różnicę, niż się wielu osobom wydaje. To właśnie ten etap oddziela „mamy problem” od „wiemy, co się wydarzyło”.
Po stronie śledczej najczęściej szuka się już nie tylko źródła ruchu, ale też infrastruktury pośredniczącej, serwerów sterujących i śladów finansowych. Dlatego warto zachować materiał od pierwszych sekund zdarzenia, nawet jeśli wydaje się mało efektowny.
Czego nie robić, bo tylko pogarsza sytuację
Są błędy, które widzę wyjątkowo często, szczególnie gdy zespół techniczny działa pod presją przełożonych lub klientów. Problem polega na tym, że część z nich daje złudzenie kontroli, a w rzeczywistości tylko zaciera ślady albo zwiększa koszt odzyskiwania usług.
- Nie kasuj logów „żeby było czyściej”. Bez nich późniejsza analiza staje się zgadywaniem.
- Nie wyłączaj monitoringu tylko dlatego, że generuje alarmy. To właśnie alarmy mówią, jak zmienia się atak.
- Nie publikuj pochopnych oskarżeń. Jeśli nie masz twardych danych, łatwo pomylić atak z awarią albo wskazać niewłaściwy podmiot.
- Nie otwieraj dodatkowych usług administracyjnych na świat, żeby „szybciej coś poprawić”. To proszenie się o większy problem.
- Nie licz na to, że jeden restart rozwiąże sprawę. Jeśli źródło ruchu nadal działa, problem wróci natychmiast.
- Nie płać pod presją bez analizy. Przy szantażu nie ma gwarancji, że atak się skończy, a często pojawia się kolejna próba wymuszenia.
To sekcja, którą zwykle warto przeczytać dwa razy. Nie dlatego, że jest odkrywcza, ale dlatego, że w realnym incydencie ludzie wracają do odruchów, a odruchy są świetne przy gaszeniu pożaru, ale słabe przy analizie ruchu sieciowego.
Co naprawdę zwiększa odporność na długą kampanię przeciążeniową
Jeśli miałbym zostawić jedną myśl praktyczną, powiedziałbym tak: odporność nie wynika z jednego narzędzia, tylko z połączenia technologii, procedur i dyscypliny zespołu. Dobrze skonfigurowany CDN, rozsądny WAF, limity na najdroższe endpointy, monitoring i gotowy kontakt do dostawcy ochrony dają znacznie więcej niż pojedynczy, „mocny” produkt kupiony po fakcie.
W dłuższej perspektywie najlepiej sprawdza się też regularny test odporności. Wystarczy symulacja raz na kilka miesięcy, przegląd logów po incydencie i sprawdzenie, czy zespół umie w 15 minut odróżnić awarię DNS od zalewu ruchu. To właśnie takie, nudne z pozoru działania najczęściej robią różnicę, gdy serwis rzeczywiście jest pod presją.
Jeżeli potraktujesz ten problem jak element bezpieczeństwa państwa, organizacji i danych użytkowników, a nie tylko kłopot techniczny, szybciej dojdziesz do stabilnej obrony. I to jest podejście, które w praktyce daje najwięcej spokoju: mniej improwizacji, więcej procedur, lepsza widoczność i szybsze zgłaszanie incydentów, zanim mała fala ruchu przerodzi się w pełny paraliż.